前端一万五 - 正则篇
本篇文章为《JavaScript 正则表达式迷你书》- 老姚的读书笔记,收获颇多,以篇记录,全文2.6w+字符。
# 字符串匹配基础
# 字符组
| 方法 | 简例 | 解释 |
|---|---|---|
| 简单字符组 | [.=+-*/] | 匹配·、=、+、-、*、/任意一个字符 |
| 排除字符组 | [^abc] | 匹配除了 abc 外的任意字符,^不写开头的话没有特殊含义 |
| 范围表示法 | [0-9a-zA-Z] | 匹配0~9、a-z、A-Z中的任意字符 |
| digit 相关(数字) | \d、\D | \d同[0-9]、\D同[^0-9] |
| word 相关(单词) | \w、\W | \w同[0-9a-zA-Z_]、\D同[^0-9a-zA-Z_] |
| white space(空白符) | \s、\S | \s表示空白符,包括空格、水平制表符、垂直制表符、换行符、回车符、换页符。\S反之 |
| 任意字符 | [\d\D]、[\w\W]、[\s\S] 和 [^] | 可匹配任意字符,包括换行 |

更多简写查询: MDN
注意事项
"[]"中的"?"、"·"就仅是匹配问号和点,无特殊含义
·可以匹配除了换行(换行符、回车符、行分隔符和段分隔符)之外的任意字符排除字符组中的
^只可以写在第一个字符, 写在[]中其他位置的无特殊含义
# 量词
字符串量词匹配分为贪婪匹配和惰性匹配
- 贪婪匹配: 尽可能的匹配最
多次。/\d{2,5}/,5->2 - 惰性匹配(在贪婪量词后加
?): 尽可能的匹配最少次。/\d{2,5}/,2->5
| 贪婪量词 | 具体含义 |
|---|---|
| {m,} | 至少出现 m 次 |
| {m} | 出现 m 次 |
| {m, n} | 出现 m 次至 n 次 |
| ? | 等价于{0, 1},出现 0 次或 1 次 |
| + | 等价于{1,},至少出现一次 |
| * | 等价于{0,},出现任意次或不出现 |
const a = /arley6{1,3}/; // arley6666666 => arley666
const b = /arley6{1,3}?/; // arley6666666 => arley6
const c = /arley6*/; // arley6666666 => arley6666666
const d = /arley6*?/; // arley6666666 => arley
const e = /.*?/; // arley6666666 => 空
const f = /.*?6/; // arley6666666 => arley6
const g = /.*?$/; // arley6666666 => arley6666666
const h = /r.*?$/; // arley6666666 => rley6666666
const i = /^r.*?$/; // arley6666666 => 空
# 逻辑或
分支结构由|分割,为惰性匹配,具体例子如下
const a = /whatever|what/; // whatever => whatever
const b = /what|whatever/; // whatever => what (惰性匹配,前面的满足条件了,就不匹配后面的)
const c = /arley what|whatever/; // arleywhatever => whatever
const d = /arley(what|whatever)/; // arleywhatever => arleywhat
# 字符串匹配例子
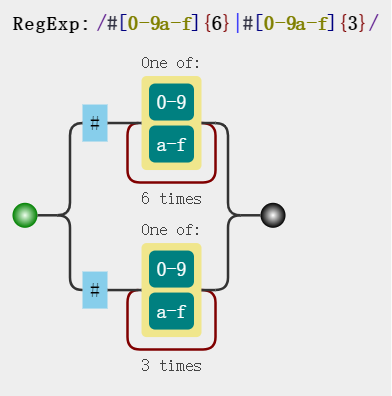
- 匹配 16 进制颜色值
const str = `#ffbbad
#Fc01DF
#FFF
#ffE`;
const reg = /#[a-f0-9]{6}|#[a-f0-9]{3}/gi;
// => 可提取为: const reg = /#([a-f0-9]{6}|[a-f0-9]{3})/ig
str.match(reg); // => ["#ffbbad", "#Fc01DF", "#FFF", "#ffE"]
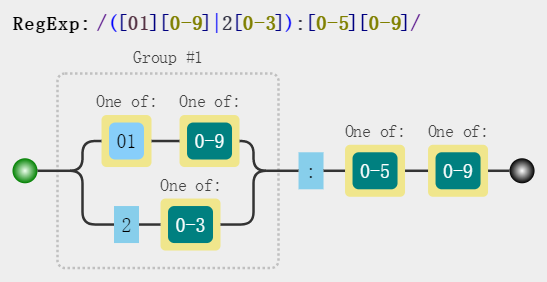
- 匹配 24 小时制时间
const str = `11:03
23:59
00:00
07:55
`;
const reg = /([01][0-9]|2[0-3]):[0-5][0-9]/gi;
str.match(reg); // => ["11:03", "23:59", "00:00", "07:55"]
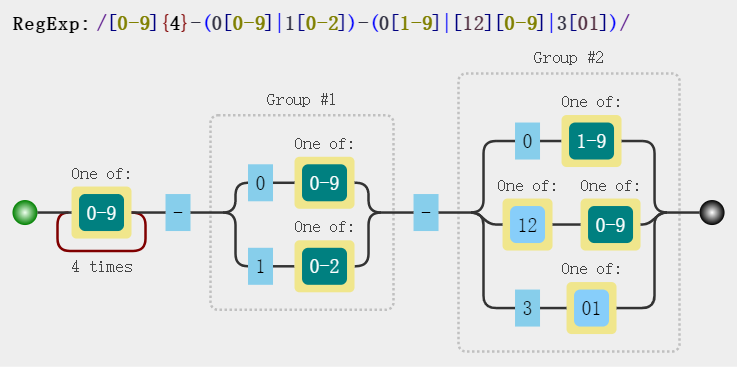
- 匹配日期
const str = `
test
a 2017-06-10 a
b 2019-11-03 b
c 2020-03-11 c
d 2020-10-11 d
`;
const reg = /[0-9]{4}-(0[0-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01])/gi;
str.match(reg); // => ["2017-06-10", "2019-11-03", "2020-03-11", "2020-10-11"]
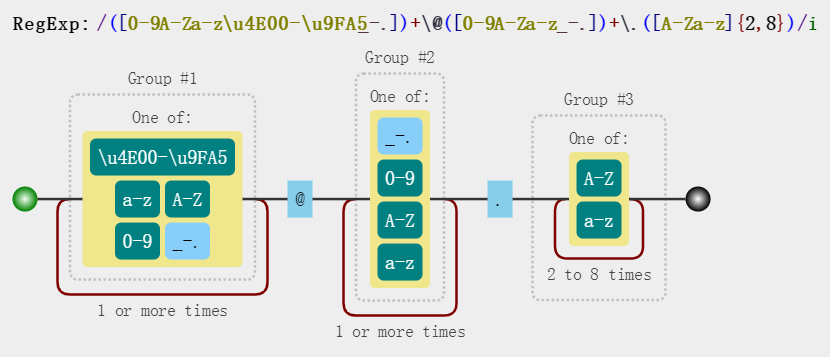
- 匹配邮箱
const str = `
132@qq.com
arley@i7xy.cn
lei@mi.com
arley@sina.com.cn
大老表@baidu.cn
`;
const reg = /([A-Za-z0-9_\-\.\u4e00-\u9fa5])+\@([A-Za-z0-9_\-\.])+\.([A-Za-z]{2,8})/gi;
str.match(reg);
# 正则表达式位置匹配
正则表达式是匹配模式,要么匹配字符,要么匹配位置。对于位置的理解,我们可以理解成空字符 ""。
比如: "hello" == "" + "h" + "" + "e" + "" + "l" + "" + "l" + "" + "o" + "";
# 如何匹配位置
| 锚 | 具体含义 |
|---|---|
| ^ | 开始 |
| $ | 结束 |
| \b | 单词边界 |
| \B | 非单词边界 |
| (?=p) | 跟随 p 的位置(不是 p 后面的字符) |
| (?!p) | 不在 p 后面的位置 |
(?=p) 就与 ^ 一样好理解,即 p 前面的那个位置
- ^ 和 $
var result = "hello".replace(/^|$/g, "#"); // => #hello#
var result = "I\nlove\njavascript".replace(/^|$/gm, "#"); // m表示多行匹配 =>
/*
#I#
#love#
#javascript#
*/
- \b 和 \B
\b 是单词边界,具体就是 \w 与 \W 之间的位置,也包括 \w 与 ^ 之间的位置,和 \w 与 $ 之间的位置
var result = "[JS] Lesson_01.mp4".replace(/\b/g, "#"); // => "[#JS#] #Lesson_01#.#mp4#"
var result = "[JS] Lesson_01.mp4".replace(/\B/g, "#"); // => "#[J#S]# L#e#s#s#o#n#_#0#1.m#p#4"
- (?=p) 和 (?!p)
(?=p),其中 p 是一个子模式,即 p 前面的位置,或者说,该位置后面的字符要匹配 p。
var result = "hello".replace(/(?=l)/g, "#"); // => "he#l#lo"
var result = "hello".replace(/(?!l)/g, "#"); // => "#h#ell#o#"
# 匹配位置示例
- 数字的千位分隔符表示法
比如把 "12345678",变成 "12,345,678"
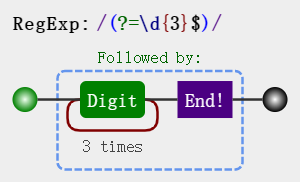
var result = "12345678".replace(/(?=\d{3}$)/g, ","); // => "12345,678"
// (?=\d{3}$) 匹配 \d{3}$ 前面的位置。而 \d{3}$ 匹配的是目标字符串最后那 3 位数字。
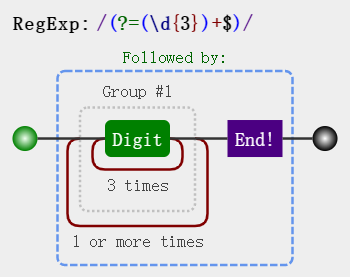
var result = "112345678".replace(/(?=(\d{3})+$)/g, ","); // => ",112,345,678"
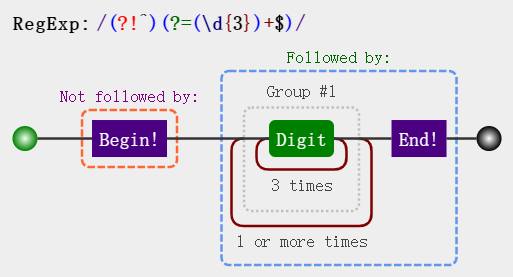
var result = "112345678".replace(/(?!^)(?=(\d{3})+$)/g, ","); // => "112,345,678"
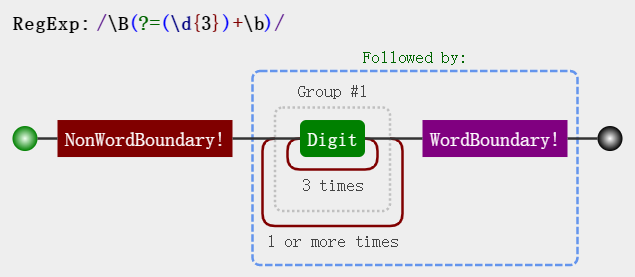
var result = "12345678 123456789".replace(/(?!\b)(?=(\d{3})+\b)/g, ",");
// => "12,345,678 123,456,789"
// (?!\b) = \B so: /\B(?=(\d{3})+\b)/g
拓展:
// 1888 => $ 1888.00
function format(num) {
return num
.toFixed(2)
.replace(/\B(?=(\d{3})+\b)/g, ",")
.replace(/^/, "$$ ");
}
console.log(format(1888));
// => "$ 1,888.00"
# 正则表达式括号的作用
- 括号内的正则是一个整体,即子表达式
# 分组和分支结构
- 分组
// 使量词 + 作用于 "ab" 这个整体
var regex = /(ab)+/g;
var string = "ababa abbb ababab";
console.log(string.match(regex));
// => ["abab", "ab", "ababab"]
- 分支结构
var regex = /^I love (JavaScript|Regular Expression)$/;
console.log(regex.test("I love JavaScript"));
console.log(regex.test("I love Regular Expression"));
// => true
// => true
# 分组引用
进行数据提取,以及更强大的替换操作
例如: 匹配日期
// var regex = /\d{4}-\d{2}-\d{2}/; // 未分组
var regex = /(\d{4})-(\d{2})-(\d{2})/; // 通过括号分组
- 提取数据
var regex = /(\d{4})-(\d{2})-(\d{2})/; //g
var string = "2017-06-12";
console.log(string.match(regex));
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"] // 不带g的结果
// ["2017-06-12"] // 带g的结果
match 返回的一个数组,第一个元素是整体匹配结果,然后是各个分组(括号里)匹配的 内容,然后是匹配下标,最后是输入的文本。另外,正则表达式是否有修饰符 g,match 返回的数组格式是不一样的。
另外也可以使用正则实例对象的 exec 方法:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
console.log(regex.exec(string));
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"]
// 测试exec 带g和不带g 结果一样,后面再深入
同时,也可以使用构造函数的全局属性(RegExp) $1 至 $9 来获取:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
regex.test(string); // 正则操作即可,例如
//regex.exec(string);
//string.match(regex);
console.log(RegExp.$1); // "2017"
console.log(RegExp.$2); // "06"
console.log(RegExp.$3); // "12"
- 替换
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, "$2/$3/$1");
console.log(result);
// => "06/12/2017"
// 等价于 ↓
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, function() {
return RegExp.$2 + "/" + RegExp.$3 + "/" + RegExp.$1;
});
console.log(result);
// => "06/12/2017"
// 或
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, function(match, year, month, day) {
return month + "/" + day + "/" + year;
});
console.log(result);
// => "06/12/2017"
# 反向引用
// 要实现的匹配数据如下:
// 2016-06-12
// 2016/06/12
// 2016.06.12
var regex = /\d{4}(-|\/|\.)\d{2}(-|\/|\.)\d{2}/;
var string1 = "2017-06-12";
var string2 = "2017/06/12";
var string3 = "2017.06.12";
var string4 = "2016-06/12"; // 错误格式, 但也会被匹配到
console.log(regex.test(string1)); // true
console.log(regex.test(string2)); // true
console.log(regex.test(string3)); // true
console.log(regex.test(string4)); // true
var regex = /\d{4}(-|\/|\.)\d{2}\1\d{2}/; // 引入反向引用,就可以解决上述问题
注意里面的 \1,表示的引用之前的那个分组 (-|/|.)。不管它匹配到什么(比如 -),\1 都匹配那个同 样的具体某个字符。 ( \2 和 \3 ... 的分别指代第二个和第三个...分组 )
- 括号嵌套了怎么办
var regex = /^((\d)(\d(\d)))\1\2\3\4$/;
var string = "1231231233";
console.log(regex.test(string)); // true
console.log(RegExp.$1); // 123 **((\d)(\d(\d)))**
console.log(RegExp.$2); // 1 (**(\d)**(\d(\d)))
console.log(RegExp.$3); // 23 ((\d)**(\d(\d))**)
console.log(RegExp.$4); // 3 ((\d)(\d**(\d)**))
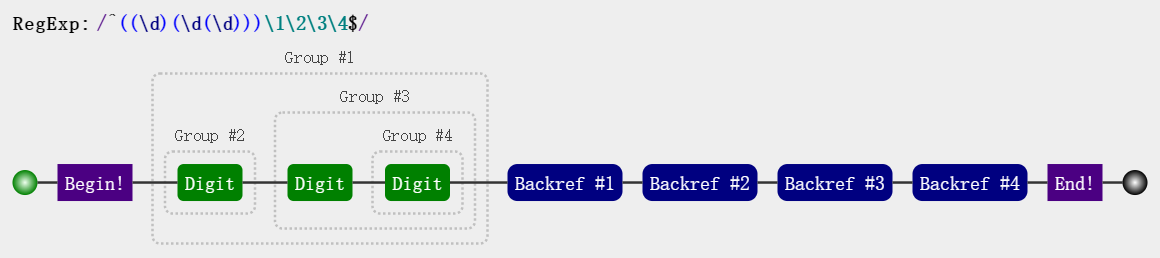
- \10 表示什么呢
var regex = /(1)(2)(3)(4)(5)(6)(7)(8)(9)(#) \10+/;
var string = "123456789# ######";
console.log(regex.test(string));
// => true
\10 是表示第 10 个分组,而不是表示\1和0(第一个分组+0)。如果真要匹配 \1 和 0 的话,请使用 (?:\1)0 或者 \1(?:0)。(?:\1):[表示非捕获括号]不要和(?=p)[匹配位置,表示 p 开头]和(?!p)[匹配位置,表示非 p 开头]混淆
- 引用不存在的分组会怎样?
var regex = /\1\2\3\4\5\6\7\8\9/;
console.log(regex.test("\1\2\3\4\5\6\789")); // true
因为反向引用,是引用前面的分组,但我们在正则里引用了不存在的分组时,此时正则不会报错,只是匹配 反向引用的字符本身。例如 \2,就匹配 "\2"。注意 "\2" 表示对 "2" 进行了转义。
- 分组后面有量词会怎样?
var regex = /(\d)+/;
var string = "12345";
console.log(string.match(regex));
// => ["12345", "5", index: 0, input: "12345"] // 分组匹配到的为5
var regex = /(\d)+ \1/;
console.log(regex.test("12345 1"));
// => false
console.log(regex.test("12345 5"));
// => true
分组后面有量词的话,分组最终捕获到的数据是最后一次的匹配。
# 非捕获括号
之前文中出现的括号,都会捕获它们匹配到的数据,以便后续引用,因此也称它们是捕获型分组和捕获型分支。 如果只想要括号最原始的功能,但不会引用它,即,既不在 API 里引用,也不在正则里反向引用。 此时可以使用非捕获括号 (?:p) 和 (?:p1|p2|p3)
var regex = /(?:ab)+/g;
var string = "ababa abbb ababab";
console.log(string.match(regex));
// => ["abab", "ab", "ababab"]
# 相关案例
- 字符串 trim 方法模拟
// trim 方法是去掉字符串的开头和结尾的空白符
function trim(str) {
return str.replace(/^\s+|\s+$/g, ""); // 匹配到开头和结尾的空白符,然后替换成空字符, 效率高
}
function trim(str) {
// 这里使用了惰性匹配 *?,不然也会匹配最后一个空格之前的所有空格的
return str.replace(/^\s*(.*?)\s*$/g, "$1"); // 匹配整个字符串,然后用引用来提取出相应的数据
}
console.log(trim(" foobar "));
- 将每个单词的首字母转换为大写
function titleize(str) {
return str.toLowerCase().replace(/(^|\s)\w/g, function(c) {
console.log("=>>>>>", c);
return c.toUpperCase();
});
}
console.log(titleize("xiaomi is a big big compony"));
- 驼峰化
// 其中分组 (.) 表示首字母。单词的界定是,前面的字符可以是多个连字符、下划线以及空白符。
// 正则后面的 ? 的目的,是为了应对 str 尾部的字符可能不是单词字符 比如 str 是 '-moz-transform '
function camelize(str) {
return str.replace(/[-_\s]+(.)?/g, function(match, c) {
return c ? c.toUpperCase() : "";
});
}
console.log(camelize("-moz-transform"));
// => "MozTransform"
- 中划线化
function dasherize(str) {
return str
.replace(/([A-Z])/g, "-$1")
.replace(/[-_\s]+/g, "-")
.toLowerCase();
}
console.log(dasherize("MozTransform"));
// => "-moz-transform"
- HTML 转义和反转义
// 将HTML特殊字符转换成等值的实体
function escapeHTML(str) {
var escapeChars = {
"<": "lt",
">": "gt",
'"': "quot",
"&": "amp",
"'": "#39"
};
const reg = new RegExp("[" + Object.keys(escapeChars).join("") + "]", "g");
console.log("JSLog: escapeHTML -> reg", reg); // /[<>"&']/g
return str.replace(reg, function(match) {
return "&" + escapeChars[match] + ";";
});
}
console.log(escapeHTML("<div>Blah blah blah</div>"));
// => "<div>Blah blah blah</div>";
// 实体字符转换为等值的HTML
function unescapeHTML(str) {
var htmlEntities = {
nbsp: " ",
lt: "<",
gt: ">",
quot: '"',
amp: "&",
apos: "'"
};
return str.replace(/\&([^;]+);/g, function(match, key) {
console.log("JSLog: unescapeHTML -> match", match);
console.log("JSLog: unescapeHTML -> key", key);
if (key in htmlEntities) {
return htmlEntities[key];
}
return match;
});
}
console.log(unescapeHTML("<div>Blah blah blah</div>"));
// => "<div>Blah blah blah</div>"
// [^] 可匹配任意字符,包括换行
console.log("<div>Blah blah blah</div>".match(/[^;]+/g));
// ["<", "div>", "Blah blah blah<", "/div>"]
console.log("<div>Blah blah blah</div>".match(/[^]+;/g));
// ["<div>Blah blah blah</div>"]
console.log("<div>Blah blah blah</div>".match(/[^]+?;/g));
// ["<", "div>", "Blah blah blah<", "/div>"]
- 匹配成对标签
// [\d\D] => 匹配任意字符
var regex = /<([^>]+)>[\d\D]*<\/\1>/; // 反向引用
var string1 = "<title>regular expression</title>";
var string2 = "<p>laoyao bye bye</p>";
var string3 = "<title>wrong!</p>";
console.log(regex.test(string1)); // true
console.log(regex.test(string2)); // true
console.log(regex.test(string3)); // false
# 正则表达式回溯
目标字符串是"abbbc",正则为/ab{1,3}bbc/匹配过程是:
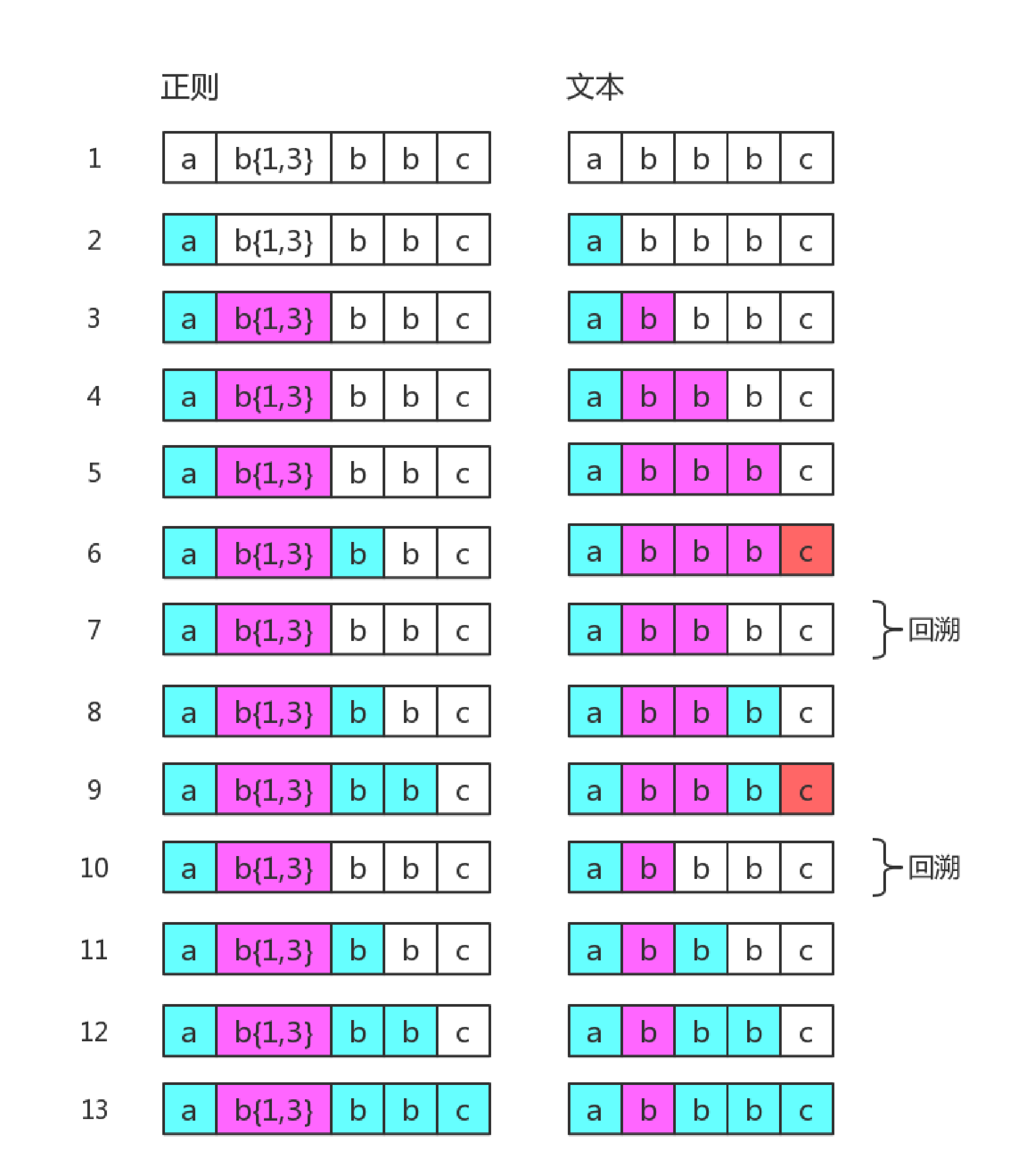
其中第 7 步和第 10 步是回溯。第 7 步与第 4 步一样,此时 b{1,3} 匹配了两个 "b"; 而第 10 步与第 3 步一样,此时 b{1,3}只匹配了一个 "b",这也是 b{1,3} 的最终匹配结果。
准确匹配的字符被通配符占据了位置,通配符匹配成功的就会被回溯,把位置还给准确匹配。
本质上就是深度优先搜索算法。其中退到之前的某一步这一过程,我们称为“回溯”。从上面的描述过程中 ,可以看出,路走不通时,就会发生“回溯”。即,尝试匹配失败时,接下来的一步通常就是回溯。
# 回溯法
回溯法也称试探法,它的基本思想是:从问题的某一种状态(初始状态)出发,搜索从这种状态出发 所能达到的所有“状态”,当一条路走到“尽头”的时候(不能再前进),再后退一步或若干步,从 另一种可能“状态”出发,继续搜索,直到所有的“路径”(状态)都试探过。这种不断“前进”、 不断“回溯”寻找解的方法,就称作“回溯法”。 - 百度百科
# 常见的回溯形式
- 贪婪量词
比如 b{1,3},因为其是贪婪的,尝试可能的顺序是从多往少的方向去尝试。首先会尝试 "bbb",然后再看整个正则是否能匹配。 不能匹配时,吐出一个 "b",即在 "bb" 的基础上,再继续尝试。如果还不行,再吐出一个,再试。如果还不行呢?只能说明匹配失败了。
如果当多个贪婪量词挨着存在,并相互有冲突时,此时会是怎样?
var string = "12345";
var regex = /(\d{1,3})(\d{1,3})/;
console.log(string.match(regex));
// => ["12345", "123", "45", index: 0, input: "12345"]
// 其中,前面的 \d{1,3} 匹配的是 "123",后面的 \d{1,3} 匹配的是 "45"
贪婪量词“试”的策略是:买衣服砍价。价钱太高了,便宜点,不行,再便宜点。
- 惰性量词
惰性量词就是在贪婪量词后面加个问号。表示尽可能少的匹配,比如:
var string = "12345";
var regex = /(\d{1,3}?)(\d{1,3})/;
console.log(string.match(regex));
// => ["1234", "1", "234", index: 0, input: "12345"]
其中 \d{1,3}? 只匹配到一个字符 "1",而后面的 \d{1,3} 匹配了 "234"。虽然惰性量词不贪,但也会有回溯的现象。
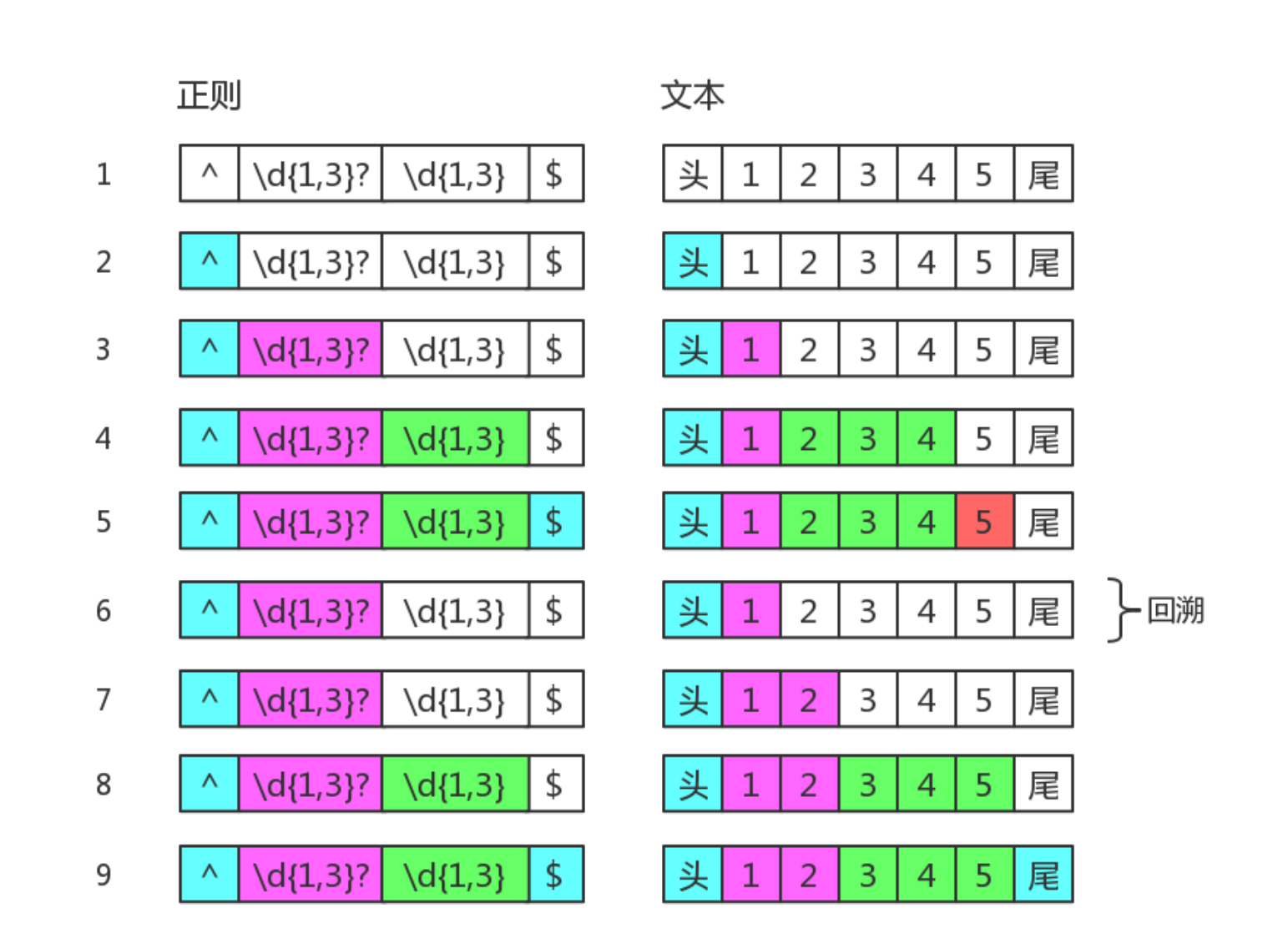
知道你不贪、很知足,但是为了整体匹配成,没办法,也只能给你多塞点了。因此最后 \d{1,3}? 匹配的字符是 "12",是两个数字,而不是一个。
惰性量词“试”的策略是:卖东西加价。给少了,再多给点行不,还有点少啊,再给点。
- 分支结构
我们知道分支也是惰性的,比如 /can|candy/,去匹配字符串 "candy",得到的结果是 "can",因为分支会一个一个尝试,如果前面的满足了,后面就不会再试验了。
分支结构,可能前面的子模式会形成了局部匹配,如果接下来表达式整体不匹配时,仍会继续尝试剩下的分支。这种尝试也可以看成一种回溯。
比如正则: /^(?:can|candy)$/
?:p表示的为括号为非捕获括号,具体可以参考之前内容,此题和?:p没太大关系,主要因素为$结束位置
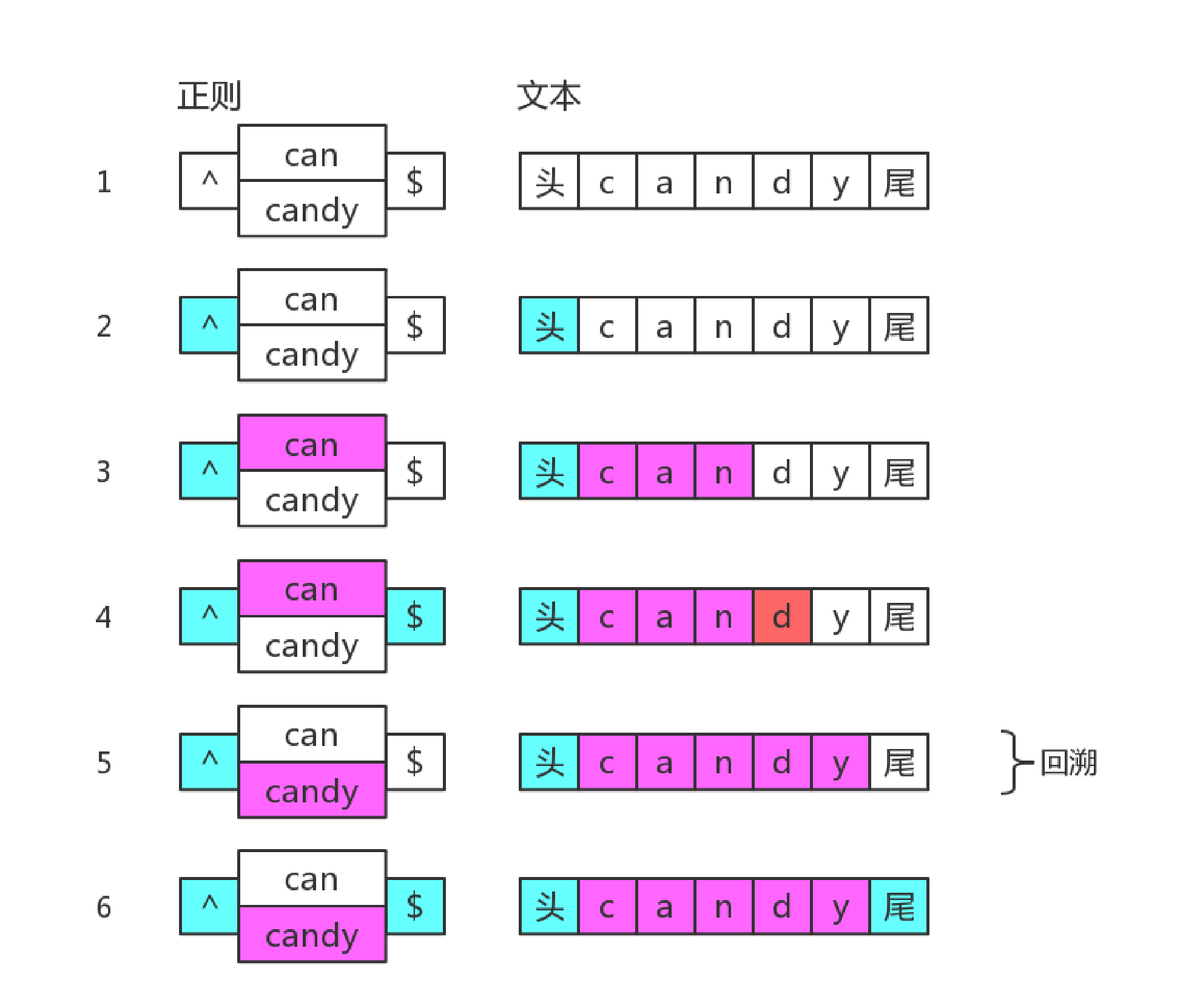
分支结构“试”的策略是:货比三家。这家不行,换一家吧,还不行,再换。
# 正则表达式的拆分(读)
# 结构和操作符
- 结构
| 结构 | 解释 |
|---|---|
| 字面量 | 匹配一个具体字符,包括不用转义的和需要转义的。比如 a 匹配字符 "a",\n 匹配换行符,\. 匹配小数点。 |
| 字符组 | 匹配一个字符,可以是多种可能之一,比如 [0-9],表示匹配一个数字。也有 \d 的简写形式。另外还有反义字符组,表示可以是除了特定字符之外任何一个字符,比如 [^0-9],表示一个非数字字符,也有 \D 的简写形式。 |
| 量词 | 表示一个字符连续出现,比如 a{1,3} 表示 "a" 字符连续出现 3 次。另外还有常见的简写形式,比如 a+ 表示 "a" 字符连续出现至少一次。 |
| 锚 | 匹配一个位置,而不是字符。比如 ^ 匹配字符串的开头,又比如 \b 匹配单词边界,又比如 (?=\d) 表示数字前面的位置。 |
| 分组 | 用括号表示一个整体,比如 (ab)+,表示 "ab" 两个字符连续出现多次,也可以使用非捕获分组 (?:ab)+。 |
| 分支 | 多个子表达式多选一,比如 abc|bcd,表达式匹配 "abc" 或者 "bcd" 字符子串。反向引用,比如 \2,表示引用第 2 个分组。 |
- 操作符
| 操作符 | 举例 | 优先级 |
|---|---|---|
| 转义符 | \ | 1 |
| 括号和方括号 | (…)、(?:…)、(?=…)、(?!…)、[…] | 2 |
| 量词限定符 | {m}、{m,n}、{m,}、?、*、+ | 3 |
| 位置和序列 | ^、$、\元字符、一般字符 | 4 |
| 管道符(竖杠) | | | 5 |
竖杠的优先级最低,即最后运算
举例分析:/ab?(c|de*)+|fg/
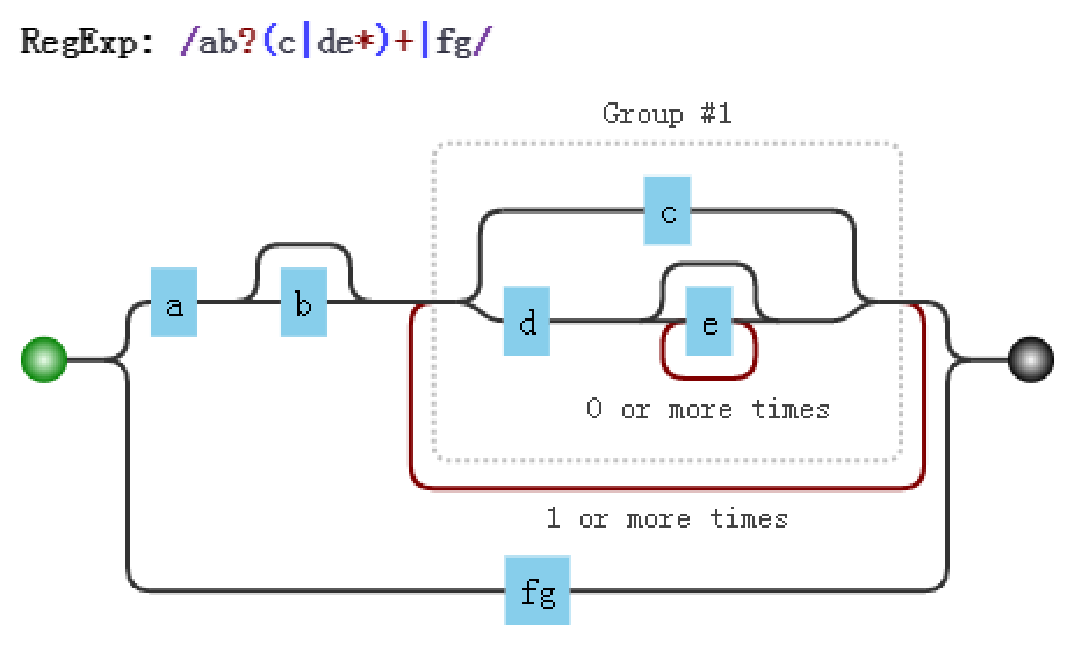
- 注意点
- 匹配字符串整体问题:
/^abc|bcd$/=>/^(abc|bcd)$/
因为是要匹配整个字符串,我们经常会在正则前后中加上锚 ^ 和 $。
比如要匹配目标字符串 "abc" 或者 "bcd" 时,如果一不小心,就会写成 /^abc|bcd$/。
而位置字符和字符序列优先级要比竖杠高,故其匹配的结构是:^abc或bcd$。正确的应打上括号/^(abc|bcd)$/。
量词连缀问题:
/^[abc]{3}+$/=>/^([abc]{3})+$/元字符转义问题(元字符: 正则中有特殊含义的字符)
总结:^、$、.、*、+、?、|、\、/、(、)、[、]、{、}、=、!、:、- ,
a. 字符组中的元字符: [、]、^、-, 开头的 ^ 必须转义,不然会把整个字符组,看成反义字符组。
b. 匹配字符组[abc] 或 量词{3,5}
var string = "[abc]";
var regex = /\[abc]/g; // 或: /\[abc\]/g, 同理: \{3,5} \{3,5\}
console.log( string.match(regex)[0] );
// => "[abc]"
c. 其余情况
比如 =、!、:、-、, 等符号,只要不在特殊结构中,并不需要转义。
但是,括号需要前后都转义的,如 /(123)/。
至于剩下的 ^、$、.、*、+、?、|、\、/ 等字符,只要不在字符组(中括号)内,都需要转义的。
# 案例分析
身份证:
/^(\d{15}|\d{17}[\dxX])$/,15位数字或18位(17位数字+(Xx|\d))IPV4 地址
ip: /^((0{0,2}\d|0?\d{2}|1\d{2}|2[0-4]\d|25[0-5])\.){3}(0{0,2}\d|0?\d{2}|1\d{2}|2[0-4]\d|25[0-5])$/
a. ((…).){3}(…)
b. (0{0,2}\d|0?\d{2}|1\d{2}|2[0-4]\d|25[0-5])
- 0{0,2}\d,匹配一位数,包括 "0" 补齐的。比如,"9"、"09"、"009";
- 0?\d{2},匹配两位数,包括 "0" 补齐的,也包括一位数;
- 1\d{2},匹配 "100" 到 "199";
- 2[0-4]\d,匹配 "200" 到 "249";
- 25[0-5],匹配 "250" 到 "255"。
# 正则表达式的构建(写)
# 平衡法则
- 匹配预期的字符串
- 不匹配非预期的字符串
- 可读性和可维护性
- 效率
# 构建正则的前提
- 是否能使用正则
比如匹配这样的字符串:1010010001…,就没有办法用正则匹配
- 是否有必要使用正则?
可以用其他函数方法实现的,就可以考虑不使用正则
- 从日期中提取出年月日
var string = "2017-07-01";
var regex = /^(\d{4})-(\d{2})-(\d{2})/;
console.log( string.match(regex) );
// => ["2017-07-01", "2017", "07", "01", index: 0, input: "2017-07-01"]
var string = "2017-07-01";
var result = string.split("-");
console.log( result );
// => ["2017", "07", "01"]
- 判断是否有问号
var string = "?id=xx&act=search";
console.log( string.search(/\?/) );
// => 0
var string = "?id=xx&act=search";
console.log( string.indexOf("?") );
// => 0
- 获取子串
var string = "JavaScript";
console.log( string.match(/.{4}(.+)/)[1] );
// => Script
var string = "JavaScript";
console.log( string.substring(4) );
// => Script
- 是否有必要构建一个复杂的正则
const reg = /(?!^[0-9]{6,12}$)(?!^[a-z]{6,12}$)(?!^[A-Z]{6,12}$)^[0-9A-Za-z]{6,12}$/ // 复杂的正则
// => 可以拆分为简单的
var regex1 = /^[0-9A-Za-z]{6,12}$/;
var regex2 = /^[0-9]{6,12}$/;
var regex3 = /^[A-Z]{6,12}$/;
var regex4 = /^[a-z]{6,12}$/;
function checkPassword (string) {
if (!regex1.test(string)) return false;
if (regex2.test(string)) return false;
if (regex3.test(string)) return false;
if (regex4.test(string)) return false;
return true;
}
# 准确性和效率
保证了准确性后,才需要是否要考虑要优化。大多数情形是不需要优化的,除非运行的非常慢,以下列出最佳实践。
- 使用具体型字符组来代替通配符,来消除回溯
// 匹配双引用号之间的字符。如,匹配字符串 123"abc"456 中的 "abc"。
// 1. /".*"/
// 2. /".*?"/
// 3. /"[^"]*"/ // 最优
- 使用非捕获型分组
(?:p)
//1. /^[-]?(\d\.\d+|\d+|\.\d+)$/
//2. /^[-]?(?:\d\.\d+|\d+|\.\d+)$/
独立出确定字符: /a+/ 可以修改成 /aa*/
提取分支公共部分
// 比如,/^abc|^def/ 修改成 /^(?:abc|def)/。
// 又比如, /this|that/修改成 /th(?:is|at)/。
- 减少分支的数量,缩小它们的范围
// /red|read/ 可以修改成 /rea?d/。
# 正则表达式编程实践
# 正则表达式的四种操作
- 验证
- 切分
- 提取
- 替换
- 验证
如:判断一个字符串中是否包含数字
var regex = /\d/;
var string = "abc123";
console.log( !!~string.search(regex) );
// => true
var regex = /\d/;
var string = "abc123";
console.log( regex.test(string) ); // 最常用
// => true
var regex = /\d/;
var string = "abc123";
console.log( !!string.match(regex) );
// => true
var regex = /\d/;
var string = "abc123";
console.log( !!regex.exec(string) );
// => true
- 切分
var regex = /,/;
var string = "html,css,javascript";
console.log( string.split(regex) );
// => ["html", "css", "javascript"]
var regex = /\D/;
console.log( "2017/06/26".split(regex) );
console.log( "2017.06.26".split(regex) );
console.log( "2017-06-26".split(regex) );
// => ["2017", "06", "26"]
// => ["2017", "06", "26"]
// => ["2017", "06", "26"]
- 提取(分组捕获)
var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2017-06-26";
console.log( string.match(regex) ); // 最常用
// =>["2017-06-26", "2017", "06", "26", index: 0, input: "2017-06-26"]
var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2017-06-26";
console.log( regex.exec(string) );
// =>["2017-06-26", "2017", "06", "26", index: 0, input: "2017-06-26"]
var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2017-06-26";
regex.test(string);
console.log( RegExp.$1, RegExp.$2, RegExp.$3 );
// => "2017" "06" "26"
var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2017-06-26";
string.search(regex);
console.log( RegExp.$1, RegExp.$2, RegExp.$3 );
// => "2017" "06" "26"
var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2017-06-26";
var date = [];
string.replace(regex, function (match, year, month, day) {
date.push(year, month, day);
});
console.log(date);
// => ["2017", "06", "26"]
- 替换
var string = "2017-06-26";
var today = new Date( string.replace(/-/g, "/") );
console.log( today );
// => Mon Jun 26 2017 00:00:00 GMT+0800 (中国标准时间)
# 相关API(重点)
// 字符串的四个方法都支持正则
String#search
String#split
String#match
String#replace
RegExp#test
RegExp#exec
- search 和 match 的参数问题
search 和 match,会把字符串转换为正则
var string = "2017.06.27";
console.log( string.search(".") );
// => 0
//需要修改成下列形式之一
console.log( string.search("\\.") );
console.log( string.search(/\./) );
// => 4
// => 4
console.log( string.match(".") );
// => ["2", index: 0, input: "2017.06.27"]
//需要修改成下列形式之一
console.log( string.match("\\.") );
console.log( string.match(/\./) );
// => [".", index: 4, input: "2017.06.27"]
// => [".", index: 4, input: "2017.06.27"]
console.log( string.split(".") );
// => ["2017", "06", "27"]
console.log( string.replace(".", "/") );
// => "2017/06.27"
- match 返回结果的格式问题
match 返回结果的格式,与正则对象是否有修饰符 g 有关
var string = "2017.06.27";
var regex1 = /\b(\d+)\b/;
var regex2 = /\b(\d+)\b/g;
console.log( string.match(regex1) );
console.log( string.match(regex2) );
// 没有 g,返回的是标准匹配格式,即,数组的第一个元素是整体匹配的内容,接下来是分组捕获的内容,然后是整体匹配的第一个下标,最后是输入的目标字符串。
// => ["2017", "2017", index: 0, input: "2017.06.27"]
// 有 g,返回的是所有匹配的内容。
// => ["2017", "06", "27"]
// 当没有匹配时,不管有无 g,都返回 null。
- exec 比 match 更强大
当正则没有 g 时,使用 match 返回的信息比较多。但是有 g 后,就没有关键的信息 index(整体匹配的第一个下标) 了。 而 exec 方法就能解决这个问题,它能接着上一次匹配后继续匹配:
var string = "2017.06.27";
var regex2 = /\b(\d+)\b/g;
console.log( regex2.exec(string) );
console.log( regex2.lastIndex); // 表示下一次匹配开始的位置, 4
console.log( regex2.exec(string) );
console.log( regex2.lastIndex);
console.log( regex2.exec(string) );
console.log( regex2.lastIndex);
console.log( regex2.exec(string) ); // null
console.log( regex2.lastIndex);
// => ["2017", "2017", index: 0, input: "2017.06.27"]
// => 4 //.
// => ["06", "06", index: 5, input: "2017.06.27"]
// => 7 //.
// => ["27", "27", index: 8, input: "2017.06.27"]
// => 10
// => null
// => 0
// 其中正则实例 lastIndex 属性,表示下一次匹配开始的位置。
在使用 exec 时,经常需要配合使用 while 循环
var string = "2017.06.27";
var regex2 = /\b(\d+)\b/g;
var result;
while ( result = regex2.exec(string) ) {
console.log( result, regex2.lastIndex );
}
// => ["2017", "2017", index: 0, input: "2017.06.27"] 4
// => ["06", "06", index: 5, input: "2017.06.27"] 7
// => ["27", "27", index: 8, input: "2017.06.27"] 10
- 修饰符 g,对 exex 和 test 的影响
字符串的四个方法,每次匹配时,都是从 0 开始的,即 lastIndex 属性始终不变。 而正则实例的两个方法 exec、test,当正则是全局匹配时,每一次匹配完成后,都会修改 lastIndex。
var regex = /a/g;
console.log( regex.test("a"), regex.lastIndex ); // => true 1
console.log( regex.test("aba"), regex.lastIndex ); // => true 3
// 因为这一次尝试匹配,开始从下标 lastIndex,即 3 位置处开始查找,自然就找不到了。
console.log( regex.test("ababc"), regex.lastIndex ); // => false 0
// 如果没有 g,自然都是从字符串第 0 个字符处开始尝试匹配:
var regex = /a/;
console.log( regex.test("a"), regex.lastIndex ); // => true 0
console.log( regex.test("aba"), regex.lastIndex ); // => true 0
console.log( regex.test("ababc"), regex.lastIndex ); // => true 0
- test 整体匹配时需要使用 ^ 和 $
console.log( /123/.test("a123b") ); // => true
console.log( /^123$/.test("a123b") ); // => false
console.log( /^123$/.test("123") ); // => true
- split 相关注意事项
var string = "html,css,javascript";
console.log( string.split(/,/, 2) ); // 可以有第二个参数,表示结果数组的最大长度
// =>["html", "css"]
var string = "html,css,javascript";
console.log( string.split(/(,)/) ); // 正则使用分组时,结果数组中是包含分隔符的:
// =>["html", ",", "css", ",", "javascript"]
- replace 是很强大的
replace 有两种使用形式,这是因为它的第二个参数,可以是字符串,也可以是函数。
- 当第二个参数是字符串
| 属性 | 具体含义 |
|---|---|
| $1,$2,…,$99 | 匹配第 1-99 个 分组里捕获的文本 |
| $& | 匹配到的子串文本 |
| $` | 匹配到的子串的左边文本 |
| $' | 匹配到的子串的右边文本 |
| $$ | 美元符号 |
例如,把 "2,3,5",变成 "5=2+3":
var result = "2,3,5".replace(/(\d+),(\d+),(\d+)/, "$3=$1+$2");
console.log(result);
// => "5=2+3"
把"2,3,5",变成 "222,333,555":
var result = "2,3,5".replace(/(\d+)/g, "$&$&$&");
console.log(result);
// => "222,333,555"
把 "2+3=5",变成 "2+3=2+3=5=5":
var result = "2+3=5".replace(/=/, "$&$`$&$'$&");
console.log(result);
// => "2+3=2+3=5=5"
// 将 = 替换为了 =2+3=5=
// $& 匹配到的子串文本 =
// $` 匹配到的子串的左边文本 2+3
// $' 匹配到的子串的右边文本 5
- 当第二个参数是函数
"1234 2345 3456".replace(/(\d)\d{2}(\d)/g, function (match, $1, $2, index, input) {
console.log([match, $1, $2, index, input]);
});
// => ["1234", "1", "4", 0, "1234 2345 3456"]
// => ["2345", "2", "5", 5, "1234 2345 3456"]
// => ["3456", "3", "6", 10, "1234 2345 3456"]
- 使用构造函数需要注意的问题
一般不推荐使用构造函数生成正则,而应该优先使用字面量。因为用构造函数会多写很多 \,除非正则需要动态生成。
var string = "2017-06-27 2017.06.27 2017/06/27";
var regex = /\d{4}(-|\.|\/)\d{2}\1\d{2}/g;
console.log( string.match(regex) );
// => ["2017-06-27", "2017.06.27", "2017/06/27"]
regex = new RegExp("\\d{4}(-|\\.|\\/)\\d{2}\\1\\d{2}", "g");
console.log( string.match(regex) );
// => ["2017-06-27", "2017.06.27", "2017/06/27"]
- 修饰符
- g: 全局匹配,即找到所有匹配的,单词是 global。
- i: 忽略字母大小写,单词是 ingoreCase
- m: 多行匹配,只影响 ^ 和 $,二者变成行的概念,即行开头和行结尾。单词是 multiline。
var regex = /\w/img;
console.log( regex.global );
console.log( regex.ignoreCase );
console.log( regex.multiline );
// => true
// => true
// => true
- source 属性
在构建动态的正则表达式时,可以通过查看该属性,来确认构建出的正则到底是什么
var className = "high";
var regex = new RegExp("(^|\\s)" + className + "(\\s|$)");
console.log( regex.source )
// => (^|\s)high(\s|$) => 即字符串"(^|\\s)high(\\s|$)"
# 代码实践整理
全篇完,此段不断积累